Designing a Language Server
With Bash++ v0.5.2, we introduced bpp-lsp: a language server for Bash++.
The Language Server Protocol (LSP) is a bit of a mess. This is owed largely to its not being governed by a committee for collective oversight, but being essentially the work of a single, very hard-working Microsoft employee. But its best quality is that it exists; that there is a standardized way to implement this functionality.
Automating the LSP
Fortunately, this hard-working programmer (Dirk Bäumer) has also graciously provided us with a machine-readable specification of the protocol, called the “Meta Model.” This is a single, massive JSON file that describes the protocol in a way that can be used to generate code for any language. So our first step was to write a generator that would take this Meta Model and produce a bunch of C++ classes to represent all the different types of messages and objects in the protocol.
The generator can be found in src/lsp/generator in the Bash++ source tree. Having this means that we never have to manually write a single line of JSON in our language server, and that our LSP implementation will always be up-to-spec.
Implementing the Language Server
For me, the best approach to starting something new is to pick a single, concrete task and do it. In doing it, you can discover the pitfalls, challenges, and broader philosophy of the larger set of problems that the task represents. So, I started by trying to implement the standard “Go to Definition” feature.
Immediately we’re confronted by the realization that the LSP makes certain assumptions about the language being served and how parsing is done. For instance, Bash++ does not use a symbol table – if you read the LSP spec, you’ll see repeated references to the concept of “symbols” which is a concept entirely alien to Bash++.
The Bash++ compiler was designed almost entirely from first principles, and the result is that the compiler operates on a set of ideas and a philosophy which is (at least apparently) somewhat unusual. Seeing this dissonance between our approach and the things that the LSP took for granted was disheartening – was I supposed to go back, and re-work the compiler to be more like other compilers?
But we can choose instead to view the problem of building a language server as “building an adapter” between our standard and their standard, like a plug converter to use a European appliance in China.
Our Approaches
This was covered a little bit in “How Does the Bash++ Compiler Work?,” but we can discuss it a bit more here.
Bash++ has a very unified concept of “entities.” A statement is an entity, a class is an entity, a method, an object, the entire program are all entities. There are code entities and ordinary entities – code entities are those that can contain code, like a method, a supershell, or the entire program. Ordinary (non-code) entities are things like classes and objects.
The result is an entity tree which maps cleanly onto the Abstract Syntax Tree.
So, how might we resolve an object reference in Bash++ source code? Take, for example, @Object.innerObject.method.
-
We declare an entity to be the current “context,” and initially set it to be the current code entity (method, supershell, etc that we’re currently in).
-
We ask this context: “Do you know about anything named
Object?” It responds and gives us a pointer to theObjectentity. -
We now set this
Objectentity as the current context, and ask it: “Do you know about anything namedinnerObject?” It responds and gives us a pointer to theinnerObjectentity. -
Finally, we ask this
innerObjectentity: “Do you know about anything namedmethod?” It responds and gives us a pointer to themethodentity.
This is very different to a symbol table lookup. Instead, we’re traversing the entity tree to find the entity that we want. I think that this approach makes a lot of conceptual sense for our language.
The Adapter
Any details that I give here are subject to change, obviously, as the language server (like the compiler) is still under development.
But let’s break down the task of implementing the “Go to Definition” feature into its component parts.
-
Receive a request from the client: The language server receives a request from the client (e.g., an IDE) to go to the definition of a “symbol.” This request includes the file path and the line/column of the “symbol.”
-
Discover the appropriate initial context entity: We have to be able to ask the parser: “Which code entity governs this line/column?”
-
Parse the relevant line: We need to parse the line of code at the given line/column to discover the “symbol” that the client is asking about. Is it an object reference? Is it an
@includestatement? -
Follow our standard procedure: Traverse the entity tree and figure out which entity is being referred to at that position in the source code.
-
Respond to the client: Finally, we send a response back to the client with the file path and line/column of the entity that was found.
Surprisingly enough, the most complicated part of this is to determine the initial context entity. There are several ways we could decide to do this, but the current implementation has the program entity store Interval Trees for each source file, mapping a code entity to a start and end position in the given file. Because of some other mathematical conveniences of our structure, we can guarantee that the innermost code entity at the given position is the code entity which (a) intersects that position, and (b) has the largest start position. But that’s just tedious implementation details. There may be other (new or established) data structures that could be better suited to the task.
So, abstractly, we get this:
src/lsp/handlers/handleDefinition.cpp:
GenericResponseMessage bpp::BashppServer::handleDefinition(const GenericRequestMessage& request) {
DefinitionRequest definition_request = request.toSpecific<DefinitionParams>();
DefinitionRequestResponse response;
response.id = request.id;
std::string uri = definition_request.params.textDocument.uri;
// ... truncated ...
std::shared_ptr<bpp::bpp_program> program = program_pool.get_program(uri);
// ... truncated ...
std::shared_ptr<bpp::bpp_entity> referenced_entity = nullptr;
// Query the program: which entity is being referenced at this position?
referenced_entity = resolve_entity_at(
uri,
position.line,
position.character,
program
);
// ... truncated ...
// Now that we know the entity, we can get its definition location.
bpp::SymbolPosition definition_location = referenced_entity->get_initial_definition();
// ... truncated ...
// Form our response and send it!
Location location;
location.uri = "file://" + definition_location.file;
location.range.start.line = definition_location.line;
location.range.start.character = definition_location.column;
location.range.end.line = definition_location.line;
location.range.end.character = definition_location.column + referenced_entity->get_name().size();
response.result = std::vector<Location>{location};
return response;
}
Advantages
The big advantage of this approach is that our language server is tied directly to our compiler – we’re using the same lexer, the same parser, the same entity tree that get used when compiling the source code.
Take a look at this output from a very common C++ language server:
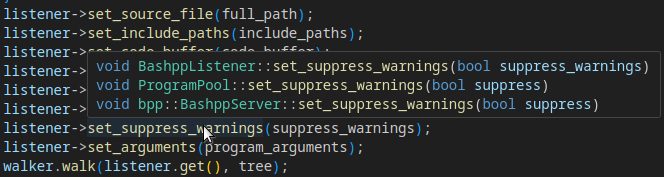
This is its response to a hover request over BashppListener::set_supress_warnings(). It knows that the codebase has several unrelated classes with member functions that share this same name, and it has absolutely no clue which function is being referred to here – so it just shows all of them.
This couldn’t happen in our language server, because we know exactly the type of the object containing the method, so we’ll know exactly which method is being referred to.
In general, this means that our language server will always be up-to-date with our compiler.
Disadvantages
The big disadvantage is exactly the same as the big advantage. Being tied directly to our compiler, which uses an ANTLR4-generated parser, means that we don’t have incremental parsing. It also means that if we change the compiler substantially, that change will have to be reflected in the language server.